
Um den Wert deiner Daten voll auszuschöpfen, ist es entscheidend, eine zentralisierte Datenspeicherung zu haben und gleichzeitig einen flexiblen Zugang zu ermöglichen.
Gerade im Analyse-, Visualisierungs- oder Reporting-Bereich, aber auch dem Marketing ist der Einsatz von ELT essentiell.
In folgendem Blog-Post habe ich für dich die Unterschiede zwischen ETL und ELT, als auch die Vor- und Nachteile festgehalten.
Effiziente Datenintegration: ETL vs. ELT – Unterschiede und Vor- und Nachteile im Vergleich
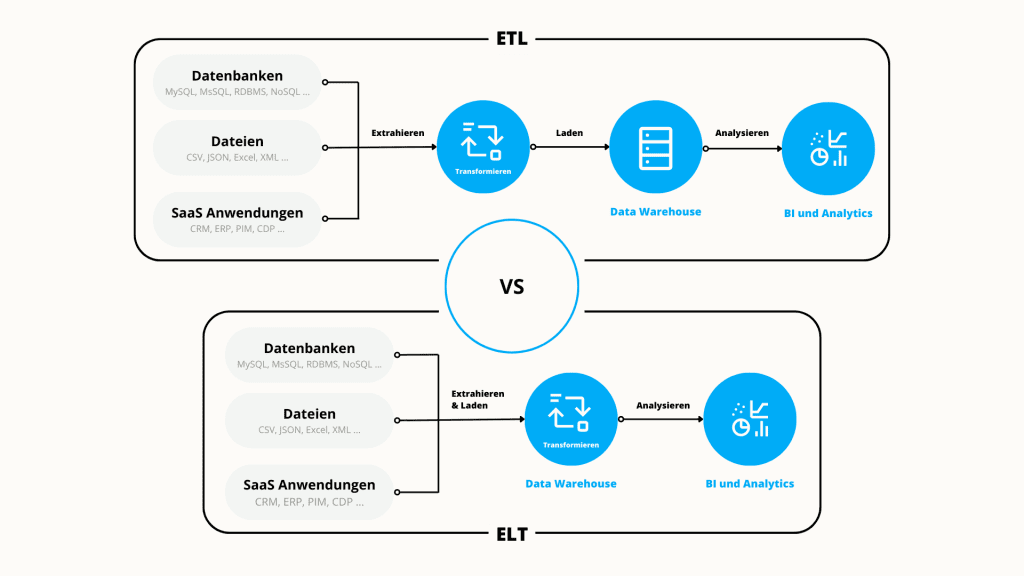
ETL (Extract, Transform, Load) und ELT (Extract, Load, Transform) sind Methoden der Datenintegration.
The Buchstaben stehen bei beiden Methoden für das Selbe: Extrahieren, Transformieren und Laden
- Extrahieren: Extrahieren bezieht sich auf den Prozess des Abrufens von Daten aus einer Quelle oder einem Datenproduzenten, wie einer Datenbank, einer XML, Excel oder einem anderen Dateiformat oder einer Softwareanwendung.
- Transformieren: Unter Transformation versteht man den Prozess der Konvertierung des Formats oder der Struktur eines Datensatzes in das Format eines Zielsystems.
- Laden: Unter Laden versteht man den Vorgang, einen Datensatz in ein Zielsystem zu überführen.
Die Hauptaufgabe beider Methoden besteht im wesentlichen darin, Daten von einem Ort zum anderen zu übertragen.
Der wichtigste Unterschied, bei ETL werden die Daten vor dem Laden in das Zielsystem umgewandelt, während sie bei ELT erst danach umgewandelt werden.
ETL
ETL ist ein Akronym für “Extrahieren, Transformieren und Laden” und beschreibt die drei Stufen der traditionellen Datenpipeline. Dabei werden Rohdaten aus der Quelle extrahiert, in einem sekundären Verarbeitungsschritt transformiert und anschließend in eine Zieldatenbank geladen.
Diese Methode wurde in den 1970er-Jahren entwickelt und ist nach wie vor bei On-Premise-Datenbanken mit begrenztem Speicher und begrenzter Verarbeitungsleistung weitverbreitet.
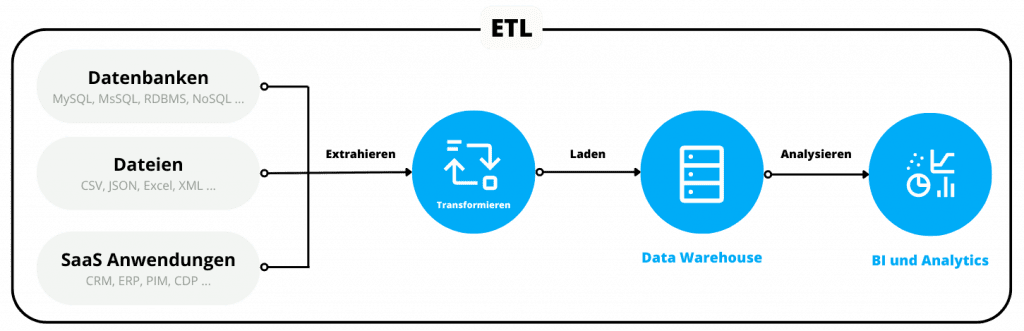
In der Vergangenheit und vor dem Aufkommen der modernen Cloud war ETL notwendig, weil Speicherplatz und Rechenleistung begrenzt und entsprechend kostenintensiv waren.
ETL ermöglichte es Unternehmen, weniger ihrer knappen technologischen Ressourcen (Rechenleistung und Speicherplatz) zu verwenden. Für alles, was man an Bandbreite und Speicherplatz einsparen konnte, musste man wiederum Unmengen an Geld für Entwickler:innen ausgeben.
Hauptproblem
Das Hauptproblem war der Mangel an Standardisierung. Die Verwendung von ETL bedeutete, dass Daten-Pipelines auf der Grundlage jeder Datenquelle und jedes Ziels meist individuell entworfen und entwickelt werden mussten. Das bedeutete, dass man Entwickler:innen mit den richtigen Fähigkeiten brauchte, um Daten-Pipelines zu erstellen, zu pflegen und weiterzuentwickeln, sobald sich die Datenquellen ändern und weiterentwickeln.
ELT
ETL steht für “Extrahieren, Laden und Transformieren”.
Dabei handelt es sich um eine Methode zur Datenaufnahme, bei der Daten aus mehreren Quellen in ein Cloud-Data-Warehouses – Snowflake, Amazon Redshift und Google BigQuery -, Data Lake oder einen Cloud-Speicher übertragen werden. Von dort aus können die Daten je nach Bedarf für verschiedene Unternehmenszwecke und Anwendungsfälle umgewandelt und verwendet werden.
Im Gegensatz zu ETL müssen beim Extrahieren, Laden und Transformieren (ELT) vor dem Ladevorgang keine Datenumwandlungen vorgenommen werden.
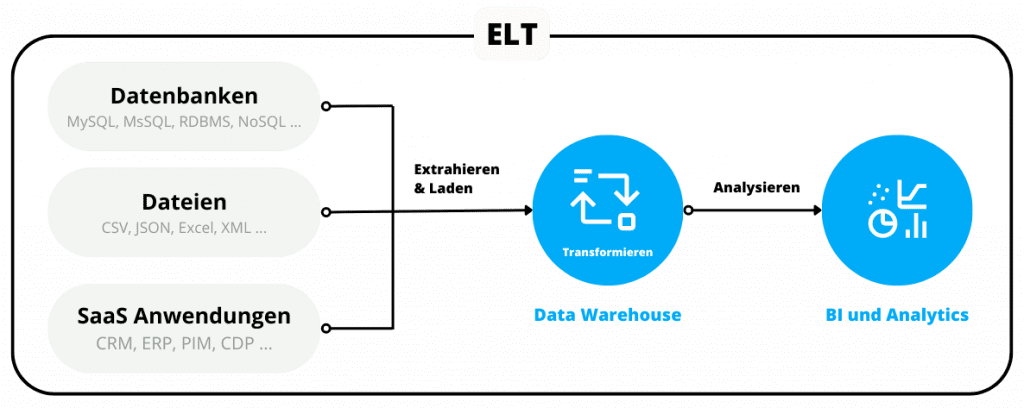
Der Nutzen von ELT ist mit der zunehmenden Dynamik, Geschwindigkeit und Menge der Daten explodiert. Und sie wird durch eine zunehmend erschwingliche Cloud-Infrastruktur ermöglicht.
Außerdem erfordert ELT im Gegensatz zu ETL weniger technische Mitarbeitende. Durch die Trennung von Extraktion und Transformation ermöglicht ELT Analysten, Transformationen mit SQL durchzuführen. Diese Idee ist der Schlüssel zum Erfolg von ELT, da sie es mehr Abteilungen ermöglicht, ihren Datenzugriff selbst zu verwalten.
Ein wesentlicher Aspekt, warum ELT so viel weniger arbeitsaufwendig ist, besteht darin, dass es eine größere Standardisierung ermöglicht.
Techniker:innen und Entwickler:innen können auf vorgefertigten Extraktions- und Ladelösungen für gängige Datenquellen aufbauen. Und für individuelle und kompliziertere Datenquellen können sie das Fachwissen externer Anbieter und die standardisierten Grundlagen von bestehenden Systemen zurückgreifen.
Vorteil
- Weniger Arbeitsaufwendig
- Kosteneffizienter
- Geschwindigkeit: Daten und Informationen immer bereit zur Verwendung
- Weniger Entwickler:innen und Techniker:innen benötigt
Was sind die Vorteile von ELT versus ETL?
Mit der ETL-Methode jedoch, bei der die Daten umgewandelt werden, bevor sie in Ihr Zielsystem geladen werden, gehst du bereits im Vorhinein von Annahmen darüber aus, wie diese Daten in der Zukunft verwendet werden.
Wenn sich die Anforderungen ändern, muss die gesamte ETL-Pipeline angepasst werden. Das erfordert unter Umständen spezielle Kenntnisse, erhöhte Sicherheitsberechtigungen und Unterstützung von Expert:innen.
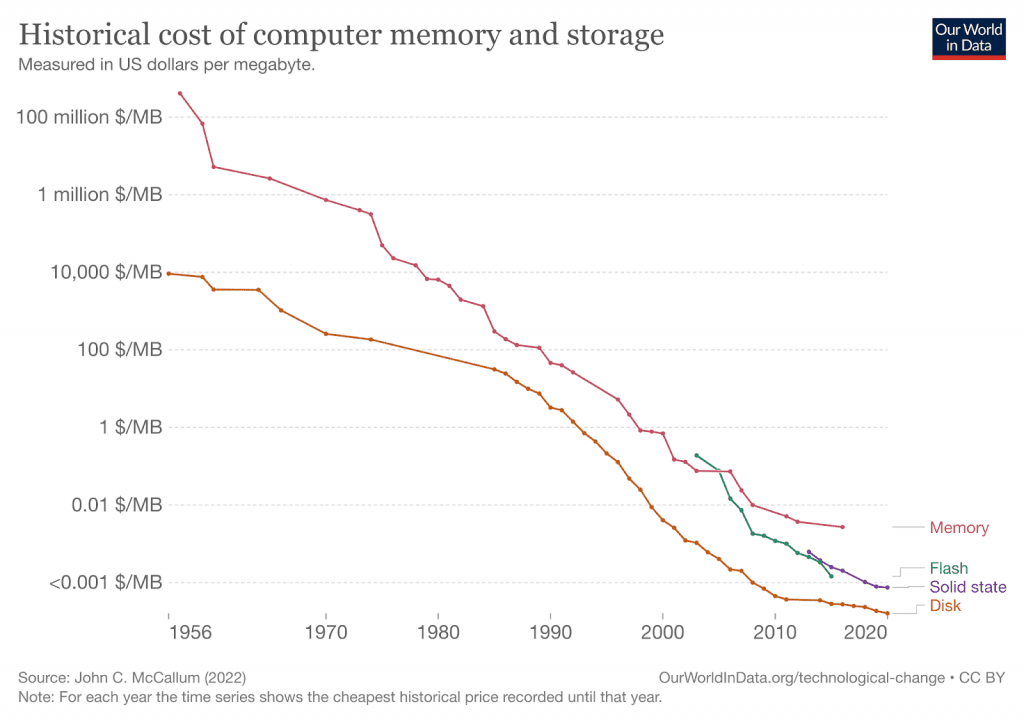
Das ETL-Paradigma entstand in den 1970er Jahren und wurde in der Vergangenheit verwendet, um Daten zu entfernen und/oder zu ändern, bevor sie an ein Ziel gesendet wurden. Das Entfernen von Daten war in der Vergangenheit aufgrund der hohen Kosten für die Rechenleistung und Speicherung notwendig. Die Kosten für die Rechen- und Speicherleistung sind jedoch im Laufe der Jahre drastisch gesunken, wie die folgende Abbildung zeigt. Dadurch sind ELT-Pipelines, die sowohl die Rohdaten als auch die umgewandelten Daten am Zielort speichern, wirtschaftlich rentabel geworden.
Im Gegensatz zu ETL entspricht der ELT-Ansatz der Realität des sich schnell ändernden Datenbedarfs. Da der ELT-Prozess die Daten nach dem Laden umwandelt, ist es nicht erforderlich, im Voraus genau zu wissen, wie die Daten verwendet werden – neue Umwandlungen können an den Rohdaten vorgenommen werden, wenn der Bedarf entsteht.
Darüber hinaus können Analysten immer auf die ursprünglichen Rohdaten zugreifen, da deren Integrität durch nachfolgende Transformationen nicht beeinträchtigt wird.
Dies gibt den Analysten Unabhängigkeit von den Entwicklern und der IT, da es nicht notwendig ist, die Pipelines zu ändern. Wenn am Zielort eine unveränderte Rohfassung der Daten vorhanden ist, können diese Daten umgewandelt werden, ohne dass eine erneute Synchronisierung der Daten aus den Quellsystemen erforderlich ist.
Fazit
Der wichtigste Unterschied zwischen beiden Methoden besteht darin, dass bei ETL die Daten vor dem Laden in das Zielsystem transformiert werden, während sie bei ELT erst nach dem Laden umgewandelt werden.
Businessanforderungen und Anforderungen an die Datenanalyse ändern sich schnell.
Daher ist ELT gerade im Analyse, Visualisierungs- oder Reporting-Bereich, aber auch Marketing essentiell.
Daten-Endanwender:innen, also Personen, die Reports erstellen, (Daten Analysten, Business Analysten, das Marketing etc.) benötigen einen flexiblen Zugriff auf diese Daten.
Denn nur dadurch können deine Daten wertstiftend für Visualisierungen und Reports für den Vertrieb, das Service-Team und das Management oder das Marketing, für Marketingmaßnahmen und Marketingautomatisierung eingesetzt werden.
Daher lässt sich im Fazit sagen, dass ETL und ELT beide Methoden zur Integration von Daten sind, die in verschiedenen Szenarien eingesetzt werden können.
