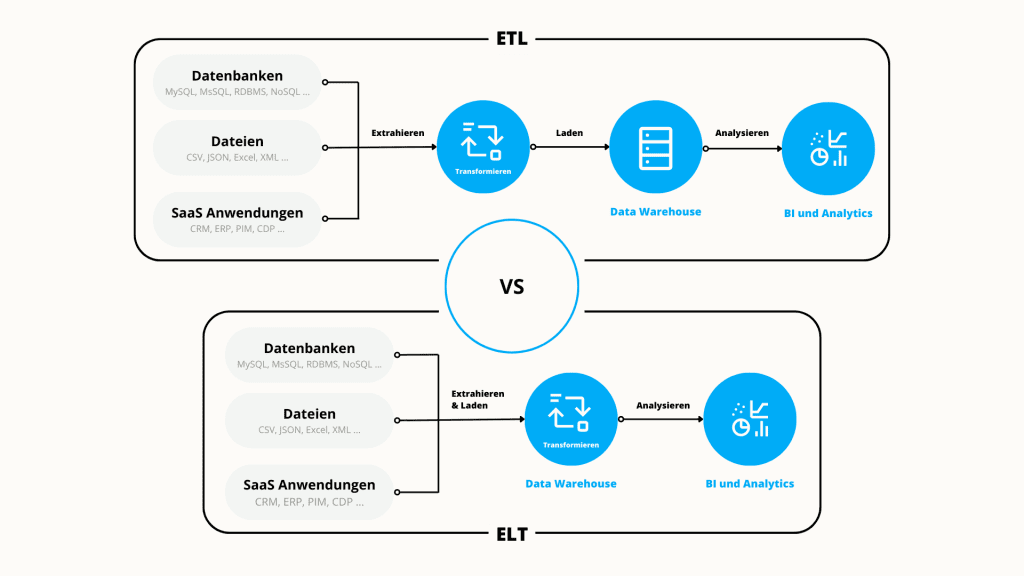
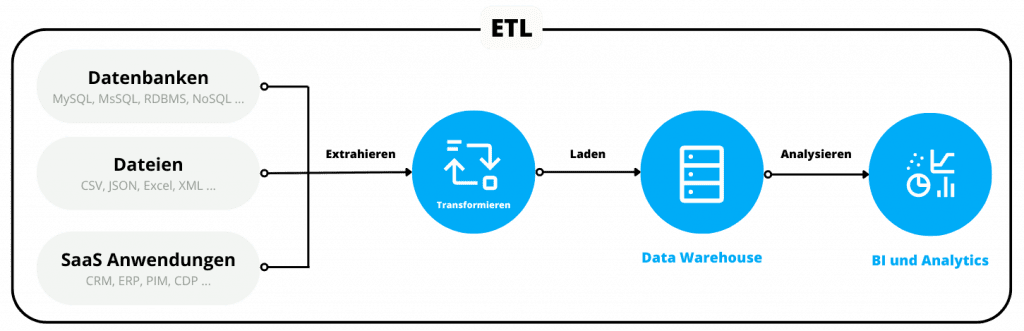
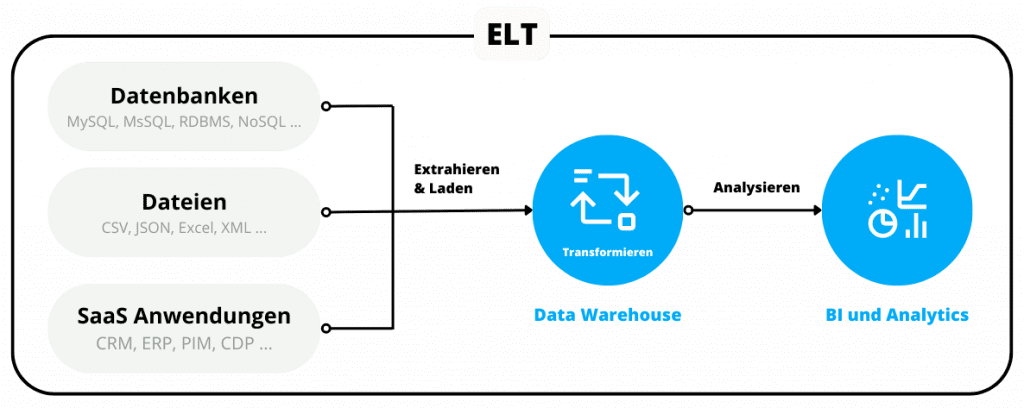
Integrationen und Schnittstellen sind für E-Commerce und SaaS-Unternehmen unverzichtbar. Sie bieten eine Vielzahl von Vorteilen, von der Steigerung der Kundenbindung bis zur Unterstützung beim Abschluss neuer Geschäfte.
Die Frage ist also nicht, ob du Integrationen erstellen sollst, sondern wie du dabei vorgehst.
Wir helfen dir, verschiedene Möglichkeiten der Integrationen aufzuzeigen, damit du entscheiden kannst, welche für dein E-Commerce oder SaaS-Unternehmen am sinnvollsten ist.
Doch zunächst wollen wir uns auf unsere Definition von Integrationen einigen und näher darauf eingehen, warum sie wichtig sind.
Definition von Integrationen
Integrationen sind wesentliche Verbindungen, die deine Anwendung mit externen Systemen und Diensten von Drittanbietern schafft. Sie bilden das technische Rückgrat für die nahtlose Interaktion zwischen unterschiedlichen Softwareprodukten und Plattformen. In der Regel nutzen Integrationen Anwendungsprogrammierschnittstellen (APIs), die es deiner Software erlaubt, Daten schnell und zuverlässig auszutauschen und Funktionen anderer Systeme zu nutzen.
Warum sind Integrationen wichtig?
Hier sind einige der wichtigsten Vorteile von Integrationen:
Ermöglicht es dir, mehr Kunden zu gewinnen
Deine Interessenten haben wahrscheinlich mehrere Kriterien, wenn sie deine Software mit Alternativen vergleichen. Dazu zählen oft Integrationen ganz oben auf ihrer Liste. Ein Beispiel: Eine Studie von Gartner hat herausgefunden, dass mehr als 80% der Käufer die Fähigkeit eines Anbieters, “nahtlose Integrationen” zu bieten, als sehr wichtig ansehen.

Hilft dir, in neue Märkte zu expandieren
Wenn du in höhere Marktsegmente vordringen, in weiteren Regionen verkaufen oder in neue Branchen eintreten möchtest, wirst du wahrscheinlich mit neuen Integrationsanforderungen konfrontiert. Wenn du diese erfüllen und über das hinausgehen kannst, was die etablierten Anbieter auf dem Markt bieten, hast du die Chance, nicht nur Fuß zu fassen, sondern auch ein Marktführer zu werden.
Erleichtert die Entwicklung deiner Kunden (Bspw. MRR & ARR Wachstum)
Integrationen sind aufgrund ihres Werts leicht zu monetarisieren.
Du kannst die Integrationen als Zusatzoptionen verkaufen, als Teil von hochwertigeren Paketen anbieten oder sogar eine spezifische Gruppe von Integrationen in einem Paket anbieten, während du in einem anderen weitere hinzufügst. Wir haben gesehen, dass unsere Kunden jeden dieser Ansätze erfolgreich umgesetzt haben. Zum Beispiel beinhaltet eine Plattform für Personalmanagement, Integrationen in ihrem Enterprise-Paket.
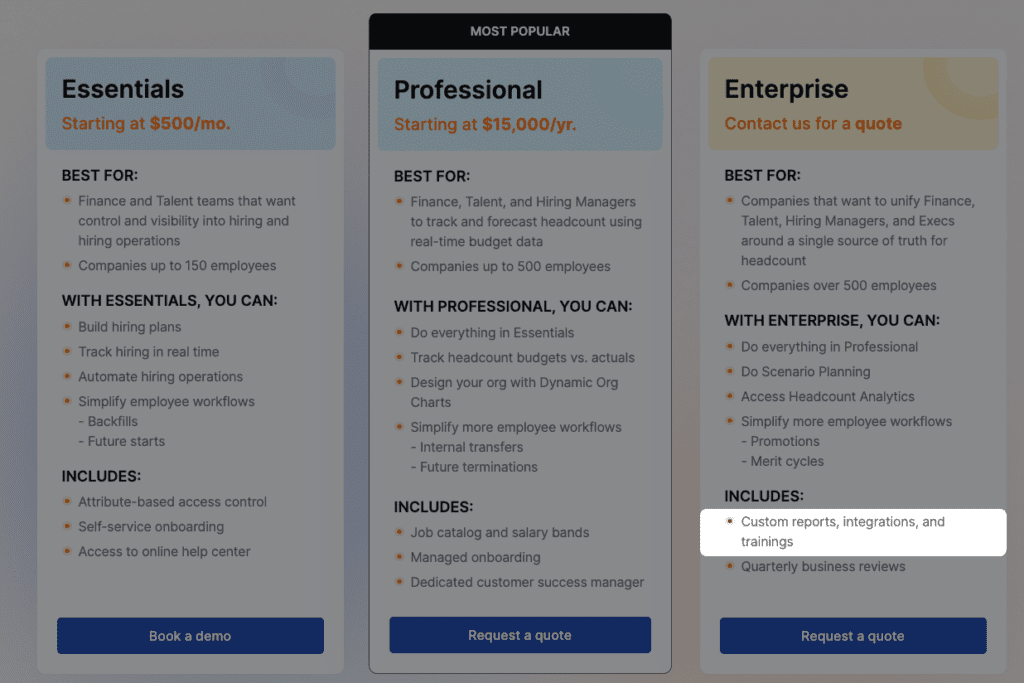
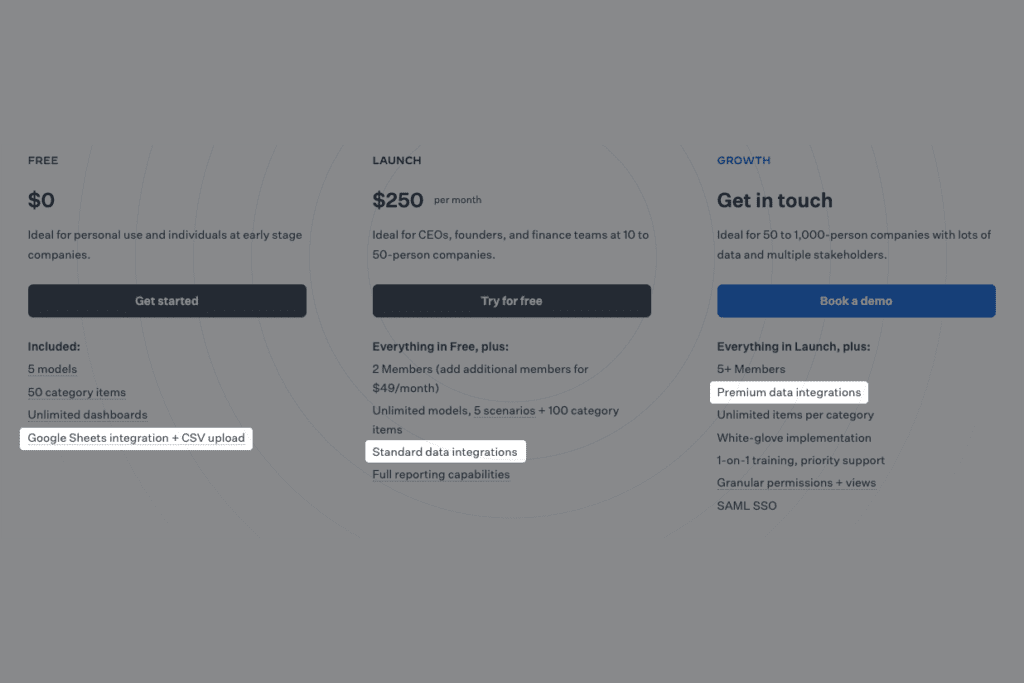
Andererseits bietet eine moderne Software für Geschäftsplanung, eine Google Sheets-Integration in ihrem kostenlosen Plan, Standard-Datenintegrationen in ihrem Launch-Plan und Premium-Integrationen in ihrem Growth-Plan an.
Ermöglicht es dir, Kundenzufriedenheit zu erhöhen
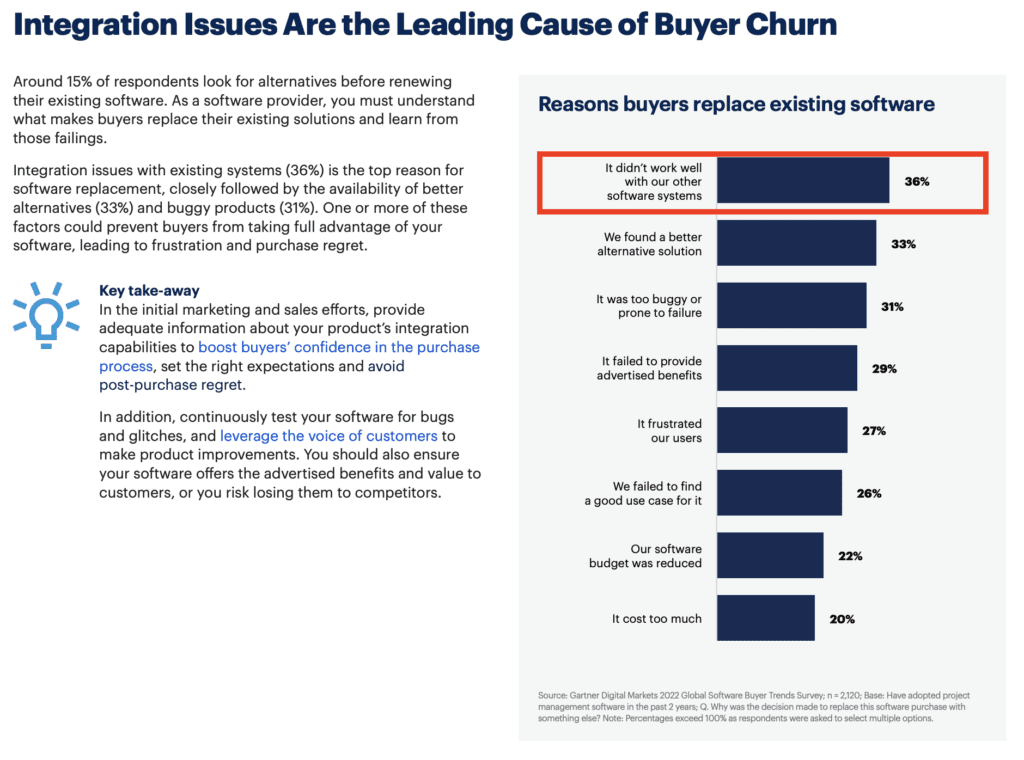
Wahrscheinlich wenig überraschend aber laut einer Gartner Studie sind Integrationsprobleme oder fehlende Integrationen der häufigste Grund für Kundenabwanderung (Churn). Anders ausgedrückt, zuverlässige und umfassende Integrationen können dabei helfen, die Kundenzufriedenheit zu erhöhen und damit verbundene Geschäftsverluste zu vermeiden.
Ansätze zur Implementierung von Integrationen
Jetzt, da du weißt, warum Integrationen wichtig sind, ist die nächste Frage, wie genau du sie umsetzen kannst.
Wir werden einige Optionen vorstellen, um deine Entscheidungsfindung zu unterstützen.
In-House Entwicklung
Das bedeutet, dass du deine internen Entwickler beauftragst, APIs von Drittanbietern zu erstellen und zu warten.
Dieser Ansatz hat einige Vorteile. Er ermöglicht es dir, die Zusammenarbeit mit Drittanbietern zu vermeiden und kann handhabbar sein, wenn du nur eine Integration benötigst oder der Umfang begrenzt ist.
In der Realität musst du jedoch wahrscheinlich eine ständig wachsende Anzahl von robusten Integrationen implementieren und pflegen. Wenn du deine Entwickler damit beauftragst, nimmt dies einen großen Teil ihrer Zeit in Anspruch und zwingt sie, andere wichtige Aufgaben zu vernachlässigen.
No-Code-/Low-Code-Integrationstools
No-Code-/Low-Code-Tools sind Plattformen, die den Prozess der Datenintegration vereinfachen wollen. Obwohl No-Code-/Low-Code-Tools ein Schritt in die richtige Richtung sind, lösen sie nicht alle Probleme der internen Entwicklung.
Sie erfordern immer noch einiges an technischem Know-how und zwingen deine Entwickler (oder die deiner Kunden) dazu, die Integrationen zu erstellen und zu verwalten. Hinzukommend fehlen häufig essentielle Integrationen, weshalb viele individuell erstellt werden müssen. Außerdem ist eine große Anzahl von Integrationen, die SaaS Unternehmen benötigen, praktisch unmöglich zu verwalten und weiterzuentwickeln.
Unified API
Eine Unified API ist eine Lösung, die mehrere Einzel-APIs von verschiedenen Diensten in einer Kategorie bündelt. Anstatt jede API einzeln anzubinden, ermöglicht sie es dir, mit nur einer Verbindung auf mehrere Dienste zuzugreifen. Das vereinfacht den Integrationsprozess erheblich, da du nicht jede API separat einrichten und verwalten musst.
Die Integration durch eine Unified API adressiert die Nachteile der anderen Optionen, indem sie es dir ermöglicht, deinen Kunden mit minimalem Aufwand umfangreiche Integrationen bereitzustellen. Zum Beispiel kannst du so die Verbindung mit den wichtigsten E-Commerce Systemen, wie Shopsysteme oder Marktplätze oder ATS-Anbietern bereitstellen, indem du deine SaaS Anwendung einfach an eine Unified API anschließt.
Dadurch kannst du Zeit und Aufwand sparen, die sonst in die Entwicklung und Pflege von einzelnen Integrationen fließen würden. Sie erleichtert es, deine Anwendungen zu skalieren, da du neue Dienste hinzufügen kannst, ohne den bestehenden Code zu ändern. So kannst du dich auf die Verbesserung deiner Produkte konzentrieren und deinen Kunden schneller bessere Dienste anbieten.
Wir wollen dir die Herausforderungen und Abhängigkeit ersparen. Seit 2017 erleichtern wir wichtige Commerce-Integrationen für Mittelständler im Handel, E-Commerce- und SaaS-Unternehmen.
Durch unsere Erfahrung mit Integrationen kannst du dich auf dein Kernprodukt konzentrieren. Wir kümmern uns um die nahtlose Anbindung deiner Kernsysteme und um die Überwachung, Weiterentwicklungen und die Kommunikation mit den 3rd-Party-API-Anbietern.